你知道什么是CPU上下文切换吗?
进程在竞争 CPU 的时候并没有真正运行,为什么还会导致系统的负载升高呢?CPU上下文切换就是罪魁祸首。
过多的上下文切换,会占用CPU过多时间(把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上),缩短真正运行时间,导致系统整体性能大幅下降。
CPU上下文
Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时进行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。
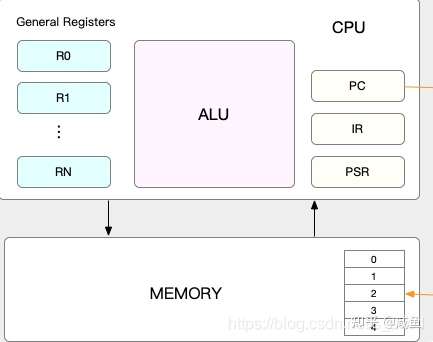
每个任务运行前,CPU都需要知道任务从哪里加载,又从哪里开始运行,也就是说任务需要系统事先帮它设置好CPU寄存器和程序计数器。
CPU寄存器,是CPU内置的容量小,但速度极快的内存。
程序计数器,则是用来存储CPU正在执行的指令位置,或者即将被执行的下一条指令位置。
CPU寄存器和程序计数器都是CPU在运行任何任务前必须依赖的环境,因此也被叫做CPU上下文。
CPU上下文切换
CPU上下文切换,就是把前一个任务的CPU上下文(寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
问题:
有人可能会觉得:CPU 上下文切换无非就是更新了 CPU 寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?
因为操作系统管理的这些任务,有很多种。例如:进程,线程,还有硬件通过触发信号,会导致中断处理程序的调用(这也是一种任务)。
根据任务的不同,CPU上下文切换就可以分为几个不同的场景,也就是:进程上下文切换,线程上下文切换和中断上下文切换。
用户空间和内核空间
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间。对应着 CPU 特权等级的 Ring 0 和 Ring 3
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
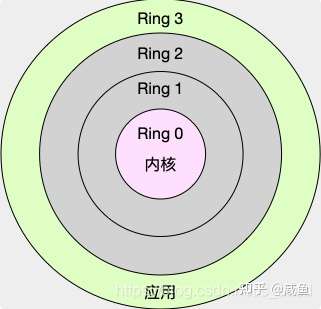
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态。陷入内核空间时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
问题:
系统调用的过程有没有发生 CPU 上下文的切换呢?
答案是肯定的。CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换(用户空间-->内核空间-->用户空间)。
需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程进程上下文切换。
进程上下文切换跟系统调用的区别
进程上下文切换,是指从一个进程切换到另一个进程去运行;系统调用过程中一直是同一个进程在运行,所以更应叫特权模式切换,而不是上下文切换。
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。

在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间,导致平均负载升高。
Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
什么时候会切换进程上下文
进程调度的时候,才需要切换上下文。
什么时候进程调度?
为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
进程上下文切换过程
接收到切换信号,挂起当前进程,记录当前进程的虚拟内存,栈等。
将这个进程在CPU中的上下文状态存储到内核中。
在内存中检索下一个进程的上下文,并将其加载到CPU寄存器中。
刷新新进程的虚拟内存和和用户栈。
最后跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程线程上下文切换。
线程与进程最大的区别在于:线程是调度的基本单位,而进程是系统资源分配的基本单位。
所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存,全局变量等资源。
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程上下文切换分为两种情况:
前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优点。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。
而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数。
等对同一个 CPU 来说,中断处理比进程拥有更高的优先级。
查看系统上下文切换情况vmstat工具一个常用的系统性能分析工具,主要用来分析系统的内存使用情况也常用来分析CPU上下文切换和中断的次数。

cs:每秒上下文切换的次数
in:每秒中断次数
r:就绪队列的长度,也就是正在运行和等待CPU进程数
b:处于不可中断睡眠状态的进程数。
此外,还可以通过pidstat工具来显示系统上下文的详细情况
# -w 显示每个进程的上下文切换情况
# 每5s显示数据
[root@promote ~]# pidstat -w 5
Linux 3.10.0-957.el7.x86_64 (promote.cache-dns.local) 2021年03月28日 _x86_64_ (1 CPU)
16时58分15秒 UID PID cswch/s nvcswch/s Command
16时58分20秒 0 3 0.60 0.00 softirqd/0
16时58分20秒 0 9 1.20 0.00 rcu_sched
16时58分20秒 0 11 0.40 0.00 watchdog/0
cswch:每秒自愿上下文切换的次数。
nvcswch:每秒非自愿上下文切换的次数。
自愿上下文切换:指进程无法获取所需资源(I/O、内存等系统资源不足)时,就会发生自愿上下文切换。
非自愿上下文切换:指进程由于时间片已用完等原因,被系统强制调度,进而发生的上下文切换。比如说大量进程都在争抢CPU时,就容易发生非自愿上下文切换案例。
该案例中,会使用sysbench工具来模拟系统多线程调度切换情况。
sysbench工具一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况
# 下载相关工具包
[root@promote ~]# yum install -y sysstat sysbench
# 查看空闲系统的上下文切换状况
# 可以看出,现在的上下文切换次数cs是45,中断次数是24,r和b都是0
[root@promote ~]# vmstat 5
procs -------memory------- ---swap-- ---io-- -system-- ----cpu---
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 255536 2108 586596 0 0 0 0 24 45 0 0 100 0 0
运行sysbench,模拟系统多线程调度的瓶颈。
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题。
[root@promote ~]# sysbench --threads=10 --max-time=300 threads run
# 运行vmstat,查看上下文切换情况
procs -------memory------- ---swap-- ---io-- -system-- ----cpu---
r b swpd free buff cache si so bi bo in cs us sy id wa st
9 0 0 247280 2108 587532 0 0 0 0 1003 1022119 24 76 0 0 0
7 0 0 247280 2108 587532 0 0 0 0 1003 1017409 22 78 0 0 0
可以发现,cs列的上下文切换次数从之前的45上升到了102万。
r 列:就绪队列的长度已经到了 9,远远超过了系统 CPU 的个数 1,所以肯定会有大量的 CPU 竞争。
us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 76%,说明 CPU 主要是被内核占用了。
in 列:中断次数也上升到了 一千左右,说明中断处理也是个潜在的问题。
结合这几个指标,我们可以知道。系统的就绪队列过长,也就是运行态和就绪态的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统CPU使用率过高。
# 查看上下文切换详细情况
[root@promote ~]# pidstat -w -u 1
平均时间: UID PID %usr %system %guest %CPU CPU Command
平均时间: 0 9174 0.00 0.04 0.00 0.04 - kworker/0:1
平均时间: 0 9185 20.82 70.82 0.00 91.63 - sysbench
17时22分57秒 UID PID cswch/s nvcswch/s Command
17时22分58秒 0 3 1.00 0.00 ksoftirqd/0
17时22分58秒 0 6 1.00 0.00 kworker/u256:0
17时22分58秒 0 9 4.00 0.00 rcu_sched
17时22分58秒 0 32 1.00 0.00 khugepaged
17时22分58秒 0 9130 1.00 0.00 sshd
17时22分58秒 0 9174 3.00 0.00 kworker/0:1
17时22分58秒 0 9199 1.00 0.00 pidstat
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 91%。
我们还发现,pidstat输出的上下文切换次数明显比vmstat的102万小太多。其实Linux 调度的基本单位实际上是线程,而我们的场景 sysbench 模拟的也是线程的调度问题。
# 输出线程的上下文切换状况
[root@promote ~]# pidstat -wt -u 1
17时24分54秒 UID TGID TID cswch/s nvcswch/s Command
17时24分55秒 0 - 9186 5755.00 97158.00 |__sysbench
17时24分55秒 0 - 9187 6402.00 96626.00 |__sysbench
17时24分55秒 0 - 9188 12300.00 86233.00 |__sysbench
17时24分55秒 0 - 9189 18358.00 72233.00 |__sysbench
17时24分55秒 0 - 9190 12099.00 89000.00 |__sysbench
17时24分55秒 0 - 9191 5381.00 101184.00 |__sysbench
17时24分55秒 0 - 9192 20376.00 67949.00 |__sysbench
17时24分55秒 0 - 9193 12865.00 81345.00 |__sysbench
17时24分55秒 0 - 9194 13570.00 87814.00 |__sysbench
17时24分55秒 0 - 9195 16084.00 82019.00 |__sysbench
可以看到,sysbench进程(主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换次数却有很多。除此之外,在上面的vmstat显示的结果里,我们还看到了中断次数也上升到了一千,对此我们要查看中断的详细信息。
中断只发生在内核态,而pidstat只是一个进程的性能分析工具,所以我们要从/proc/interrupts 这个只读文件中读取。
/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
# 查看中断使用状况
[root@promote ~]# watch -d cat /proc/interrupts
CPU0 ...RES: 2450431 Rescheduling interrupts...
最后,总结一下
自愿上下文切换变多了,一般是I/O瓶颈非自愿上下文切换变多了,一般是CPU资源不足,多个进程争抢CPU中断次数变多了,说明CPU被中断处理程序占用,需要查看/proc/interrupts 文件来分析具体的中断类型。
留言评论